aideveloper-toolssystems thinking
How to Make AI Agents Work: Less Magic, More Harness Engineering
AI agents work better when given appropriate context and guardrails.
There used to be a high barrier to writing telemetry. I knew that I should do it, but it was hard to justify when it took hours away from feature work. I am not an OpenTelemetry expert. In the past, I would get stuck even trying to send a basic trace because of challenging syntax and unclear documentation.
Now, I instrument everything. Not because I suddenly became an OpenTelemetry expert, but because Claude handles all the tedious parts while I focus on what actually matters: understanding what my code is doing in production.
I'd be deep in feature development, thinking I was close to done. Then, I'd remember: "Oh right, I should probably add some tracing to this."
I'd have to context-switch from product logic to infrastructure concerns. I'd open the OpenTelemetry docs in another tab, trying to remember the difference between a span and a trace, what attributes I'm supposed to set, and how to properly handle errors without breaking my instrumentation.
The worst part wasn't even the technical complexity. It was the mental overhead. Should this attribute be service.name or service_name? Do I need to manually create child spans, or does the library handle it? What's the right way to add custom attributes?
Then I'd show what I put together to the OpenTelemetry experts I work with (we have a lot of them at Honeycomb) and they'd point out issues that I would've never caught.
Now, it's much more straightforward. I describe the shape of a trace that I'd like to see to Claude. Sometimes I even draw diagrams! I ask it to take a pass at writing the telemetry, and give it access to the Honeycomb MCP server so that it can check its own work.
Eventually, it'll come back to me saying it's done, so I check the UI in Honeycomb to confirm. Now when I show it to OpenTelemetry experts, they still have feedback but it's very simple and fast to iterate on.
Last week I was trying to figure out whether my agent documentation files — things like CLAUDE.md and project rules — were actually getting loaded consistently into my Claude Code sessions. I had a bunch of context files, but I had no way to tell if they were all making it in every time, or if some were silently being skipped. I also couldn't tell if the reason the agent wasn't adhering to my guidelines was because it was never reading them, or because they had too much context in them and they were overloading it.
Claude Code supports hooks — shell commands that run automatically at different points in its lifecycle. I realized I could use hooks to send telemetry to Honeycomb and actually see which files get loaded in each session. In the old days, wiring up OpenTelemetry for something like this would have gone straight onto my "do it later" pile. Instead, I paired with Claude to build the whole thing.
I described what I wanted: a hook that fires on key lifecycle events — session start, instructions loaded, tool use, prompt submit — and sends a span to Honeycomb with the relevant context. Claude wrote the scripts, set up the OTel exporter config, and I wired them into my .claude/settings.json:
Within minutes I had traces flowing into Honeycomb showing the full lifecycle of each Claude Code session. Here's what one of those traces looks like:
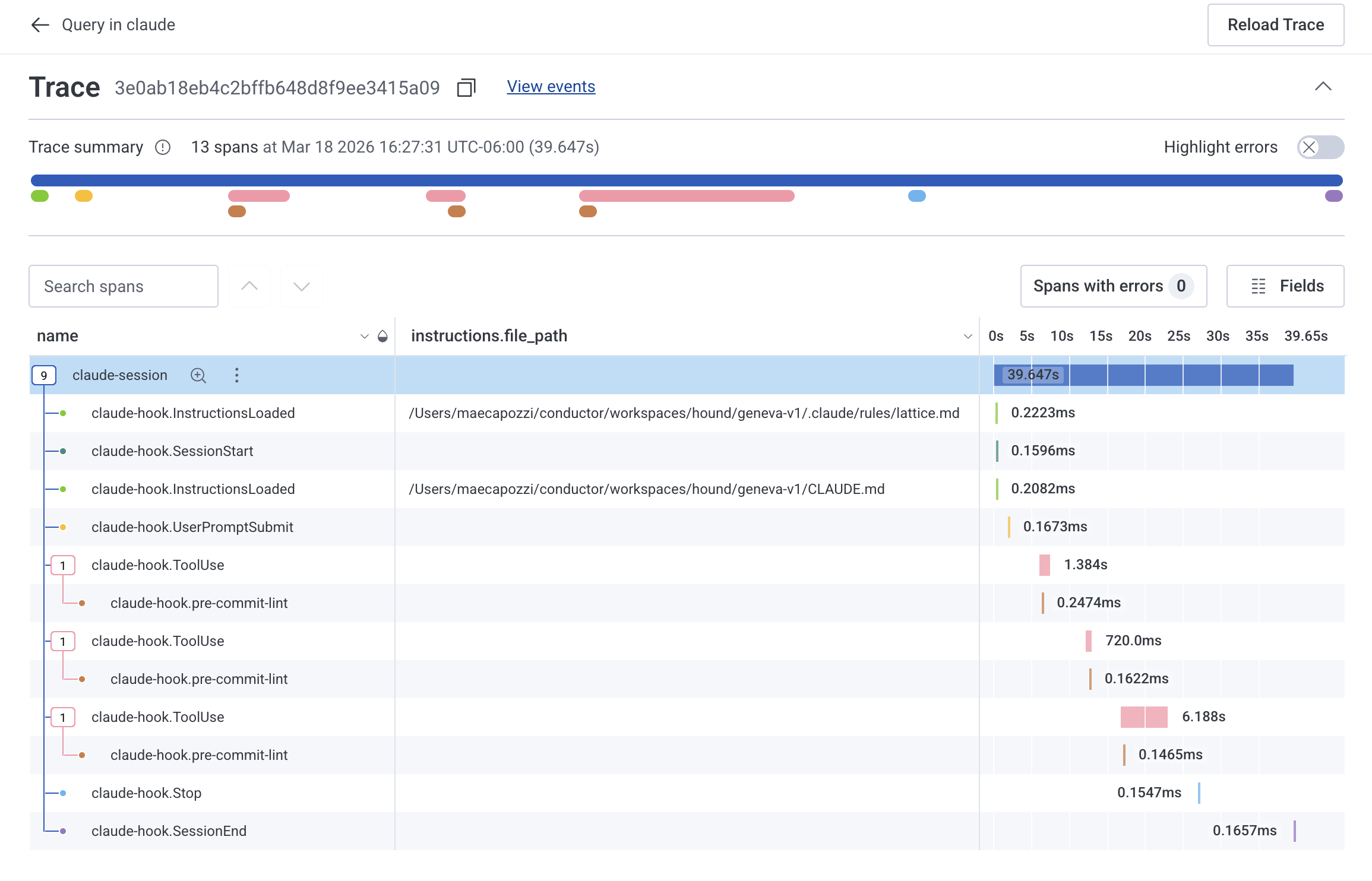
The InstructionsLoaded spans were the key insight. Each one carries an instructions.file_path attribute showing exactly which file got loaded — like .claude/rules/lattice.md (our design system rules) or CLAUDE.md. I could immediately see which documentation files were making it into each session and spot when one was missing.
Claude wrote the OpenTelemetry boilerplate, picked the right exporter config, and structured the span attributes in a way that made the data immediately useful for querying. That would have taken me an hour of docs-diving on my own.
Complete observability became essential once I started using AI to write more of my code.
Whether you're using agents to generate significant portions of your codebase or not, you don't have a deep mental model of every line. Abstraction is not a bad thing. It lets you move faster and focus on higher-level concerns. But it creates cognitive debt. You understand what the code should do, but you might not immediately know why it's failing when something goes wrong in production.
Cognitive debt existed before agents, and observability was important then too. But as the amount of code being shipped is rapidly increasing, observability has become even more critical.
I don't even consider not including telemetry anymore. It's part of writing the feature. When instrumentation takes minutes, there's no reason to skip it.
This pattern extends beyond my own workflow. When AI removes tooling friction, practices that used to be optional become standard. There's a lot of discourse about AI-generated slop. And it's true that in the hands of non-engineers, AI agents can go off the rails and create indecipherable and unmaintainable codebases extremely quickly.
I'm still bullish on AI agents for software engineering because I think it reduces the difficult tradeoffs an engineer needs to make. In the past, I might've skipped writing telemetry to hit a deadline. But now, adding telemetry takes minutes. It's no longer a trade-off between velocity and operational excellence. You can have both.
If you're still treating observability as optional, try it on something small this week. Describe what you want to measure, let Claude handle the boilerplate, and see what you can learn from it.
AI agents work better when given appropriate context and guardrails.
I've been using Claude Code to offload tedious parts of platform engineering: dependency reviews, generating test PRs, dependency migrations, and project cleanup.
I used to block out weeks for tooling migrations. Now I let Claude Code run in the background, check in when it's done, and pair with it to understand what changed.