aiobservabilitydeveloper-tools
AI agents removed the friction from writing telemetry
I used to avoid adding telemetry because it felt like tedious busywork. Now with Claude handling the OpenTelemetry boilerplate, I'm instrumenting everything.
Over the past year, I've been exploring how the Software Development Lifecycle is changing as AI agents become more powerful.
I came back from holiday break to an essay by Steve Yegge called "Welcome to Gas Town". He describes his orchestration system for running 20-30 concurrent AI coding agents. After reading it, I thought it was an interesting experiment, but I didn't see how I could apply it to my day-to-day tasks at work.
Then I found Katherine Cass's "Agent System v1 Architecture", where she's got 11 named agents coordinating via message bus, running 24/7 like an engineering team that never sleeps.
Reading about these experiments made me want to build my own system –– one that I understood and could trust to actually do work for me in a production system.
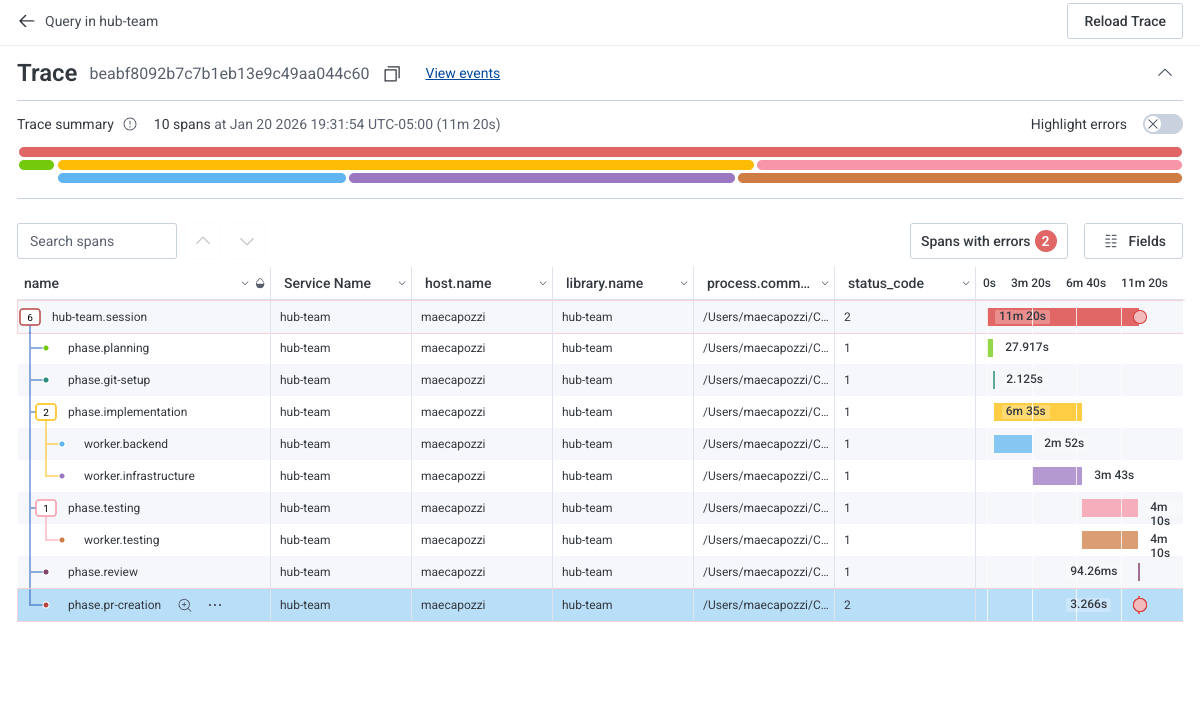
So I built hub-team. It's a multi-agent orchestrator that coordinates specialized Claude Code agents through a 6-phase workflow. It does not run 24/7 (yet) because I still want granular control over what tasks it's taking on, and in what order.
Hub-team runs tasks through six phases: Planning, Git Setup, Implementation, Testing, Review, and PR Creation. I landed on this structure after trying a few other approaches. Having clear boundaries between phases makes debugging way easier when something goes wrong.

The phases aren't just organizational; they're recovery points. If the implementation phase fails, I still have a clean worktree. If the testing phase fails, I know the code exists but doesn't work yet. Each phase has its own timeout, its own telemetry span, its own failure mode.
Instead of hardcoding "if frontend task, spawn frontend agent," I have a coordinator agent that reads the task and decides which specialists to invoke. The coordinator gets a prompt that explains the available specialists, (Frontend, Backend, Infrastructure, Testing), and returns a structured response saying which ones are needed.
This means the routing logic lives in natural language, not code. When I want to change how tasks get routed, I edit a markdown file, not TypeScript.
The coordinator can also reject tasks. If someone asks for something that doesn't make sense or violates security boundaries, the coordinator says no and explains why.
Each specialist runs as a separate Claude Code process. I spawn them with Node's child_process.spawn(), pass in the working directory (the isolated worktree), and pipe their output to the console.
The tricky part is timeouts. An agent can get stuck. Maybe it's waiting for user input that'll never come, maybe it's in a loop. I settled on 15 minutes per specialist and 10 minutes for the coordinator. If an agent exceeds its timeout, I kill the entire process group (not just the parent process) to make sure nothing lingers.
That negative PID is important. Without it, you might kill the parent but leave zombie children running.
This was one of those ideas that seemed obvious in retrospect.
Instead of having agents work directly in my repo, each task gets its own git worktree. It's a lightweight copy of the repo at a specific commit, stored in /tmp/linear-{issueId}.
The workflow looks like this:
origin/main/tmpIf something goes wrong, I just delete the worktree. My main repo stays clean. And because worktrees are cheap, I could theoretically run multiple tasks in parallel without conflicts.
I wanted to see the entire workflow in one trace, from task input through PR creation, including all the agent work in between. The problem is that each agent runs as a separate process. How do you maintain trace continuity across process boundaries?
OpenTelemetry has a solution: the TRACEPARENT environment variable. When I spawn an agent, I pass the current trace context as an environment variable:
The agent picks this up and creates child spans under that parent. In Honeycomb, I can see the entire workflow as a single trace: the planning phase, the git setup, each specialist's work, testing, PR creation. When something takes too long or fails, I can see exactly where.
If you're thinking about building your own Claude Code multi-agent architecture, here are the patterns I found most useful:
TRACEPARENT environment variables to maintain observability across agent boundaries.These patterns work well whether you're running two agents or twenty. The key is that each agent has a clear scope and the coordinator manages the big picture.
Parallel specialist execution. Right now specialists run sequentially. If a task needs both frontend and backend work, backend waits for frontend to finish. There's no technical reason for this, I just haven't built the coordination logic yet.
Better error recovery. If a specialist fails, the whole workflow stops. I'd like to have the coordinator re-evaluate and maybe try a different approach, or at least give me a useful summary of what went wrong.
Smarter testing. The testing specialist runs after implementation, but it doesn't know what changed. I'd like to pass it context about which files were modified so it can run targeted tests instead of the full suite.
I think so. hub-team certainly isn't production-ready. I wouldn't feel comfortable letting it loose without supervision on a production codebase. But I am able to use it for tasks that have been in my backlog for months. And I'm heavily using it to build out an app outside of my regular workday that I'm hoping to eventually launch..
I used to avoid adding telemetry because it felt like tedious busywork. Now with Claude handling the OpenTelemetry boilerplate, I'm instrumenting everything.
AI agents work better when given appropriate context and guardrails.
I've been using Claude Code to offload tedious parts of platform engineering: dependency reviews, generating test PRs, dependency migrations, and project cleanup.